Cybermap.co.id Pengenalan suara, atau speech recognition, telah berkembang pesat menjadi salah satu teknologi yang paling menjanjikan dan transformatif di era digital ini. Dulu dianggap sebagai fiksi ilmiah, kini teknologi ini telah merambah ke berbagai aspek kehidupan kita, mulai dari asisten virtual di smartphone hingga sistem kendali suara di mobil dan rumah pintar. Artikel ini akan mengupas tuntas tentang teknologi pengenalan suara, mulai dari prinsip kerjanya, perkembangannya, berbagai aplikasi, tantangan yang dihadapi, hingga potensi masa depannya.
Apa Itu Teknologi Pengenalan Suara?
Teknologi pengenalan suara (speech recognition), juga dikenal sebagai Automatic Speech Recognition (ASR), adalah kemampuan sebuah mesin atau program untuk mengidentifikasi kata-kata yang diucapkan dan mengubahnya menjadi format teks yang dapat dipahami oleh komputer. Proses ini melibatkan serangkaian algoritma kompleks yang menganalisis gelombang suara, mengidentifikasi pola-pola linguistik, dan mencocokkannya dengan model akustik yang telah dilatih sebelumnya.
Secara sederhana, teknologi ini memungkinkan kita untuk berinteraksi dengan perangkat elektronik hanya dengan menggunakan suara. Kita bisa memerintahkan smartphone untuk menelepon seseorang, meminta asisten virtual untuk memutar musik, atau bahkan mendiktekan email tanpa perlu mengetik.
Bagaimana Cara Kerja Teknologi Pengenalan Suara?
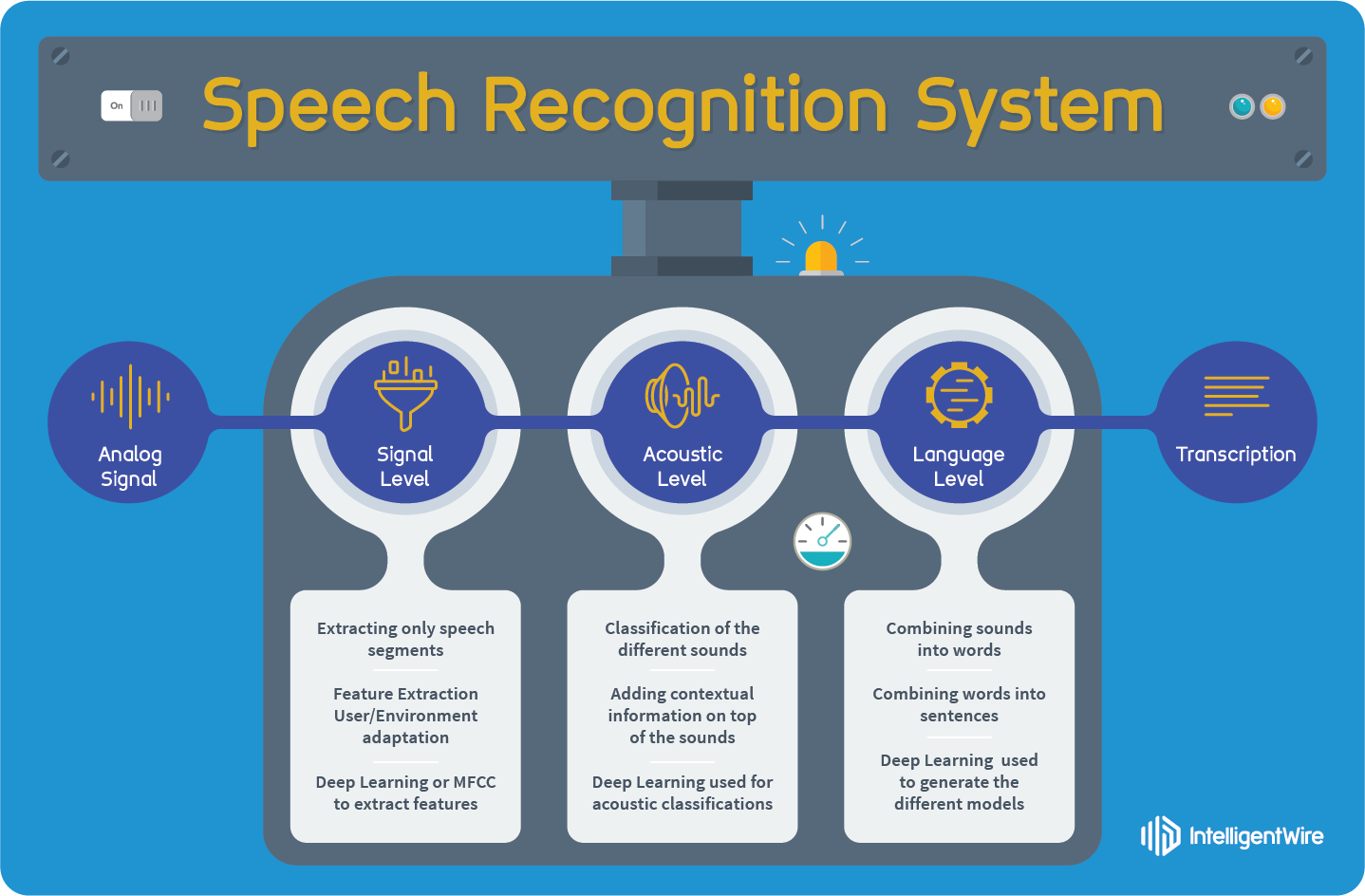
Proses pengenalan suara melibatkan beberapa tahapan utama, yaitu:
Akuisisi Suara (Audio Acquisition): Tahap ini melibatkan penangkapan suara menggunakan mikrofon. Kualitas mikrofon sangat penting karena akan memengaruhi akurasi pengenalan suara.
Pra-pemrosesan (Pre-processing): Suara yang ditangkap kemudian diproses untuk menghilangkan noise dan distorsi. Tahap ini melibatkan teknik-teknik seperti noise reduction, echo cancellation, dan voice activity detection (VAD). VAD berfungsi untuk mengidentifikasi bagian audio yang mengandung ucapan dan membuang bagian yang tidak relevan (misalnya, keheningan).
Ekstraksi Fitur (Feature Extraction): Pada tahap ini, karakteristik penting dari sinyal suara diekstraksi. Fitur-fitur ini merepresentasikan informasi akustik yang unik dari setiap fonem (satuan bunyi terkecil dalam bahasa). Salah satu teknik ekstraksi fitur yang paling umum digunakan adalah Mel-Frequency Cepstral Coefficients (MFCC). MFCC mengubah sinyal suara menjadi representasi matematis yang meniru cara telinga manusia memproses suara.
Pemodelan Akustik (Acoustic Modeling): Model akustik adalah representasi statistik dari fonem dan kata-kata. Model ini dilatih menggunakan data audio yang sangat besar dan bervariasi. Model akustik yang baik akan mampu membedakan antara fonem yang berbeda dan memperkirakan probabilitas kemunculan setiap fonem dalam sebuah kata. Hidden Markov Models (HMM) adalah salah satu teknik yang paling sering digunakan untuk pemodelan akustik.
Pemodelan Bahasa (Language Modeling): Model bahasa memberikan informasi tentang struktur dan probabilitas kemunculan kata-kata dalam sebuah bahasa. Model ini membantu sistem pengenalan suara untuk memprediksi kata-kata yang paling mungkin diucapkan berdasarkan konteks kalimat. Model bahasa dapat berupa n-gram models, yang memperkirakan probabilitas sebuah kata berdasarkan n kata sebelumnya, atau model bahasa berbasis jaringan saraf tiruan (neural networks).
Dekoding (Decoding): Pada tahap terakhir, sistem pengenalan suara menggunakan model akustik dan model bahasa untuk mencari urutan kata yang paling mungkin sesuai dengan sinyal suara yang diinput. Proses ini melibatkan algoritma pencarian yang kompleks, seperti Viterbi algorithm.
Perkembangan Teknologi Pengenalan Suara
Teknologi pengenalan suara telah mengalami perkembangan yang signifikan sejak pertama kali dikembangkan pada tahun 1950-an. Awalnya, sistem pengenalan suara sangat terbatas, hanya mampu mengenali kata-kata yang diucapkan secara terisolasi oleh satu orang. Namun, seiring dengan kemajuan teknologi komputer dan pengembangan algoritma yang lebih canggih, kemampuan sistem pengenalan suara terus meningkat.
Beberapa tonggak penting dalam perkembangan teknologi pengenalan suara meliputi:
- 1950-an: Pengembangan sistem pengenalan suara pertama oleh Bell Labs. Sistem ini hanya mampu mengenali digit angka yang diucapkan secara terisolasi.
- 1960-an: Pengembangan sistem pengenalan suara yang mampu mengenali beberapa ratus kata.
- 1970-an: Pengembangan Hidden Markov Models (HMM), yang menjadi dasar bagi banyak sistem pengenalan suara modern.
- 1980-an: Pengembangan sistem pengenalan suara berbasis PC.
- 1990-an: Pengembangan sistem pengenalan suara yang lebih akurat dan robust terhadap noise.
- 2000-an: Munculnya aplikasi pengenalan suara di perangkat mobile.
- 2010-an: Pemanfaatan deep learning dalam pengenalan suara, yang menghasilkan peningkatan akurasi yang signifikan.
Saat ini, teknologi pengenalan suara telah mencapai tingkat akurasi yang sangat tinggi, bahkan dalam lingkungan yang bising dan dengan aksen yang berbeda. Hal ini sebagian besar berkat kemajuan dalam deep learning, khususnya penggunaan jaringan saraf tiruan (neural networks) seperti recurrent neural networks (RNN) dan convolutional neural networks (CNN).
Aplikasi Teknologi Pengenalan Suara
Teknologi pengenalan suara memiliki berbagai aplikasi di berbagai bidang, antara lain:
- Asisten Virtual: Asisten virtual seperti Siri, Google Assistant, dan Alexa menggunakan teknologi pengenalan suara untuk memahami perintah suara pengguna dan memberikan respons yang relevan.
- Transkripsi Otomatis: Teknologi ini digunakan untuk mengubah rekaman audio atau video menjadi teks secara otomatis. Aplikasi ini sangat berguna dalam bidang jurnalisme, hukum, dan pendidikan.
- Kontrol Suara: Teknologi ini memungkinkan pengguna untuk mengontrol perangkat elektronik hanya dengan menggunakan suara. Aplikasi ini banyak digunakan di mobil, rumah pintar, dan perangkat wearable.
- Dictation Software: Perangkat lunak dikte memungkinkan pengguna untuk menulis teks hanya dengan berbicara. Aplikasi ini sangat berguna bagi orang-orang yang memiliki disabilitas fisik atau kesulitan mengetik.
- Layanan Pelanggan: Teknologi pengenalan suara digunakan dalam sistem IVR (Interactive Voice Response) untuk mengarahkan pelanggan ke departemen yang tepat atau memberikan informasi yang dibutuhkan.
- Pendidikan: Teknologi ini dapat digunakan untuk membantu siswa belajar bahasa asing, meningkatkan kemampuan membaca, dan memberikan umpan balik otomatis terhadap pengucapan.
- Kesehatan: Teknologi pengenalan suara dapat digunakan untuk membantu dokter dan perawat mendokumentasikan catatan medis, memberikan instruksi kepada pasien, dan memantau kondisi kesehatan pasien dari jarak jauh.
Tantangan dalam Pengembangan Teknologi Pengenalan Suara
Meskipun telah mencapai kemajuan yang signifikan, teknologi pengenalan suara masih menghadapi beberapa tantangan, antara lain:
- Noise dan Distorsi: Akurasi pengenalan suara dapat sangat dipengaruhi oleh noise dan distorsi dalam lingkungan sekitar.
- Aksen dan Dialek: Sistem pengenalan suara seringkali kesulitan mengenali ucapan dengan aksen atau dialek yang berbeda.
- Bahasa yang Kompleks: Beberapa bahasa memiliki struktur dan tata bahasa yang lebih kompleks daripada bahasa lain, sehingga lebih sulit untuk dikenali oleh sistem pengenalan suara.
- Emosi dan Intonasi: Emosi dan intonasi dapat memengaruhi cara seseorang berbicara, sehingga menyulitkan sistem pengenalan suara untuk mengidentifikasi kata-kata yang diucapkan.
- Data Training yang Terbatas: Pengembangan model akustik dan model bahasa yang akurat membutuhkan data training yang sangat besar dan bervariasi.
Masa Depan Teknologi Pengenalan Suara
Masa depan teknologi pengenalan suara sangat cerah. Dengan terus berkembangnya teknologi deep learning dan semakin banyaknya data yang tersedia, sistem pengenalan suara akan menjadi lebih akurat, robust, dan adaptif.
Beberapa tren yang diperkirakan akan memengaruhi perkembangan teknologi pengenalan suara di masa depan meliputi:
- Penggunaan Deep Learning yang Lebih Luas: Deep learning akan terus menjadi mesin penggerak utama dalam pengembangan teknologi pengenalan suara.
- Pengembangan Sistem Pengenalan Suara Multilingual: Sistem pengenalan suara akan semakin mampu mengenali berbagai bahasa dan dialek.
- Integrasi dengan Teknologi Lain: Teknologi pengenalan suara akan semakin terintegrasi dengan teknologi lain seperti artificial intelligence (AI), natural language processing (NLP), dan computer vision.
- Pengembangan Aplikasi Baru: Teknologi pengenalan suara akan terus melahirkan aplikasi-aplikasi baru yang inovatif di berbagai bidang.
Sebagai kesimpulan, teknologi pengenalan suara telah menjadi bagian integral dari kehidupan kita sehari-hari dan akan terus memainkan peran yang semakin penting di masa depan. Dengan terus berkembangnya teknologi ini, kita dapat berharap untuk melihat aplikasi-aplikasi baru yang akan membuat hidup kita lebih mudah, efisien, dan menyenangkan.